汇编基础
汇编
汇编语言(assembly language)是一种用于电子计算机、微处理器、微控制器或其他可编程器件的低级语言,亦称为符号语言。在汇编语言中,用助记符(Mnemonics)代替机器指令的操作码,用地址符号(Symbol)或标号(Label)代替指令或操作数的地址。在不同的设备中,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令。普遍地说,特定的汇编语言和特定的机器语言指令集是一一对应的,不同平台之间不可直接移植。
汇编语言直接同计算机的底层软件甚至硬件进行交互,它具有如下一些优点:
能够直接访问与硬件相关的存储器或 I/O 端口;
能够不受编译器的限制,对生成的二进制代码进行完全的控制;
能够对关键代码进行更准确的控制,避免因线程共同访问或者硬件设备共享引起的死锁;
能够根据特定的应用对代码做最佳的优化,提高运行速度;
能够最大限度地发挥硬件的功能。
同时还应该认识到,汇编语言是一种层次非常低的语言,它仅仅高于直接手工编写二进制的机器指令码,因此不可避免地存在一些缺点:
编写的代码非常难懂,不好维护;
很容易产生 bug,难于调试;
只能针对特定的体系结构和处理器进行优化;
开发效率很低,时间长且单调。
寄存器
32位CPU所含有的寄存器有:
4个数据寄存器(EAX、EBX、ECX和EDX)
2个变址和指针寄存器(ESI和EDI) 2个指针寄存器(ESP和EBP)
6个段寄存器(ES、CS、SS、DS、FS和GS)
1个指令指针寄存器(EIP) 1个标志寄存器(EFlags)
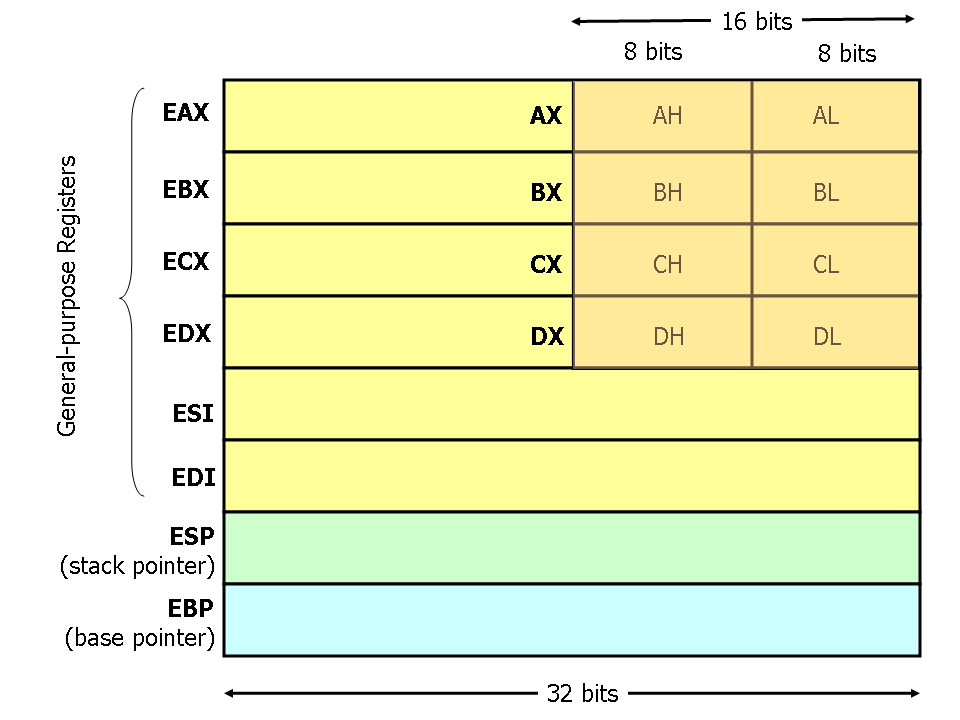
X86处理器中有8个32位的通用寄存器。由于历史的原因,EAX通常用于计算,ECX通常用于循环变量计数。ESP和EBP有专门用途,ESP指示栈指针(用于指示栈顶位置),而EBP则是基址指针(用于指示子程序或函数调用的基址指针)。如图中所示,EAX、EBX、ECX和EDX的前两个高位字节和后两个低位字节可以独立使用,其中两位低字节又被独立分为H和L部分,这样做的原因主要是考虑兼容16位的程序。应用寄存器时,其名称大小写是不敏感的,如EAX和eax没有区别。
数据寄存器
数据寄存器主要用来保存操作数和运算结果等信息,从而节省读取操作数所需占用总线和访问存储器的时间。
32位CPU有4个32位的通用寄存器EAX、EBX、ECX和EDX。对低16位数据的存取,不会影响高16位的数据。这些低16位寄存器分别命名为:AX、BX、CX和DX,它和先前的CPU中的寄存器相一致。
4个16位寄存器又可分割成8个独立的8位寄存器(AX:AH-AL、BX:BH-BL、CX:CH-CL、DX:DH-DL),每个寄存器都有自己的名称,可独立存取。程序员可利用数据寄存器的这种“可分可合”的特性,灵活地处理字/字节的信息。
寄存器AX和AL通常称为累加器(Accumulator),用累加器进行的操作可能需要更少时间。累加器可用于乘、除、输入/输出等操作,它们的使用频率很高;寄存器BX称为基地址寄存器(Base Register)。它可作为存储器指针来使用;寄存器CX称为计数寄存器(Count Register)。在循环和字符串操作时,要用它来控制循环次数;在位操作中,当移多位时,要用CL来指明移位的位数;寄存器DX称为数据寄存器(Data Register)。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址.
在16位CPU中,AX、BX、CX和DX不能作为基址和变址寄存器来存放存储单元的地址,但在32位CPU中,其32位寄存器EAX、EBX、ECX和EDX不仅可传送数据、暂存数据保存算术逻辑运算结果,而且也可作为指针寄存器,所以,这些32位寄存器更具有通用性。
变址寄存器
32位CPU有2个32位通用寄存器ESI和EDI。其低16位对应先前CPU中的SI和DI,对低16位数据的存取,不影响高16位的数据。
寄存器ESI、EDI、SI和DI称为变址寄存器(Index Register),它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。
变址寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。它们可作一般的存储器指针使用。在字符串操作指令的执行过程中,对它们有特定的要求,而且还具有特殊的功能。
指针寄存器
32位CPU有2个32位通用寄存器EBP和ESP。其低16位对应先前CPU中的SBP和SP,对低16位数据的存取,不影响高16位的数据。
寄存器EBP、ESP、BP和SP称为指针寄存器(Pointer Register),主要用于存放堆栈内存储单元的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。指针寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。
它们主要用于访问堆栈内的存储单元,并且规定:
BP为基指针(Base Pointer)寄存器,用它可直接存取堆栈中的数据;
SP为堆栈指针(Stack Pointer)寄存器,用它只可访问栈顶。
段寄存器
段寄存器是根据内存分段的管理模式而设置的。内存单元的物理地址由段寄存器的值和一个偏移量组合而成的,这样可用两个较少位数的值组合成一个可访问较大物理空间的内存地址。
CPU内部的段寄存器:
CS——代码段寄存器(Code Segment Register),其值为代码段的段值;
DS——数据段寄存器(Data Segment Register),其值为数据段的段值;
ES——附加段寄存器(Extra Segment Register),其值为附加数据段的段值;
SS——堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值;
FS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值;
GS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值。
在16位CPU系统中,它只有4个段寄存器,所以,程序在任何时刻至多有4个正在使用的段可直接访问;在32位微机系统中,它有6个段寄存器,所以,在此环境下开发的程序最多可同时访问6个段。
32位CPU有两个不同的工作方式:实方式和保护方式。在每种方式下,段寄存器的作用是不同的。有关规定简单描述如下:
实方式:前4个段寄存器CS、DS、ES和SS与先前CPU中的所对应的段寄存器的含义完全一致,内存单元的逻辑地址仍为“段值:偏移量”的形式。为访问某内存段内的数据,必须使用该段寄存器和存储单元的偏移量。
保护方式:在此方式下,情况要复杂得多,装入段寄存器的不再是段值,而是称为“选择子”(Selector)的某个值。
指令指针寄存器
32位CPU把指令指针扩展到32位,并记作EIP,EIP的低16位与先前CPU中的IP作用相同。
指令指针EIP、IP(Instruction Pointer)是存放下次将要执行的指令在代码段的偏移量。在具有预取指令功能的系统中,下次要执行的指令通常已被预取到指令队列中,除非发生转移情况。所以,在理解它们的功能时,不考虑存在指令队列的情况。
在实方式下,由于每个段的最大范围为64K,所以,EIP中的高16位肯定都为0,此时,相当于只用其低16位的IP来反映程序中指令的执行次序
标志寄存器
运算结果标志位
1、进位标志CF(Carry Flag)
进位标志CF主要用来反映运算是否产生进位或借位。如果运算结果的最高位产生了一个进位或借位,那么,其值为1,否则其值为0。使用该标志位的情况有:多字(字节)数的加减运算,无符号数的大小比较运算,移位操作,字(字节)之间移位,专门改变CF值的指令等。
2、奇偶标志PF(Parity Flag)
奇偶标志PF用于反映运算结果中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。
利用PF可进行奇偶校验检查,或产生奇偶校验位。在数据传送过程中,为了提供传送的可靠性,如果采用奇偶校验的方法,就可使用该标志位。
3、辅助进位标志AF(Auxiliary Carry Flag)
在发生下列情况时,辅助进位标志AF的值被置为1,否则其值为0:
(1)在字操作时,发生低字节向高字节进位或借位时;
(2)在字节操作时,发生低4位向高4位进位或借位时。
对以上6个运算结果标志位,在一般编程情况下,标志位CF、ZF、SF和OF的使用频率较高,而标志位PF和AF的使用频率较低。
4、零标志ZF(Zero Flag)
零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。在判断运算结果是否为0时,可使用此标志位。
5、符号标志SF(Sign Flag)
符号标志SF用来反映运算结果的符号位,它与运算结果的最高位相同。在微机系统中,有符号数采用补码表示法,所以,SF也就反映运算结果的正负号。运算结果为正数时,SF的值为0,否则其值为1。
6、溢出标志OF(Overflow Flag)
溢出标志OF用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0。
状态控制标志位
状态控制标志位是用来控制CPU操作的,它们要通过专门的指令才能使之发生改变。
1、追踪标志TF(Trap Flag)
当追踪标志TF被置为1时,CPU进入单步执行方式,即每执行一条指令,产生一个单步中断请求。这种方式主要用于程序的调试。
指令系统中没有专门的指令来改变标志位TF的值,但程序员可用其它办法来改变其值。
2、中断允许标志IF(Interrupt-enable Flag)
中断允许标志IF是用来决定CPU是否响应CPU外部的可屏蔽中断发出的中断请求。但不管该标志为何值,CPU都必须响应CPU外部的不可屏蔽中断所发出的中断请求,以及CPU内部产生的中断请求。具体规定如下:
(1)当IF=1时,CPU可以响应CPU外部的可屏蔽中断发出的中断请求;
(2)当IF=0时,CPU不响应CPU外部的可屏蔽中断发出的中断请求。
CPU的指令系统中也有专门的指令来改变标志位IF的值。
3、方向标志DF(Direction Flag)
方向标志DF用来决定在串操作指令执行时有关指针寄存器发生调整的方向。具体规定在第5.2.11节——字符串操作指令——中给出。在微机的指令系统中,还提供了专门的指令来改变标志位DF的值。
32位标志寄存器增加的标志位
1、I/O特权标志IOPL(I/O Privilege Level)
I/O特权标志用两位二进制位来表示,也称为I/O特权级字段。该字段指定了要求执行I/O指令的特权级。如果当前的特权级别在数值上小于等于IOPL的值,那么,该I/O指令可执行,否则将发生一个保护异常
2、嵌套任务标志NT(Nested Task)
嵌套任务标志NT用来控制中断返回指令IRET的执行。具体规定如下:
(1)当NT=0,用堆栈中保存的值恢复EFLAGS、CS和EIP,执行常规的中断返回操作;
(2)当NT=1,通过任务转换实现中断返回。
3、重启动标志RF(Restart Flag)
重启动标志RF用来控制是否接受调试故障。规定:RF=0时,表示“接受”调试故障,否则拒绝之。在成功执行完一条指令后,处理机把RF置为0,当接受到一个非调试故障时,处理机就把它置为1。
4、虚拟8086方式标志VM(Virtual 8086 Mode)
如果该标志的值为1,则表示处理机处于虚拟的8086方式下的工作状态,否则,处理机处于一般保护方式下的工作状态
内存和寻址模式
声明静态数据区
可以在X86汇编语言中用汇编指令.DATA声明静态数据区(类似于全局变量),数据以单字节、双字节、或双字(4字节)的方式存放,分别用DB,DW, DD指令表示声明内存的长度。在汇编语言中,相邻定义的标签在内存中是连续存放的。
.DATA
var DB 64 ;声明一个字节,并将数值64放入此字节中
var2 DB ? ; 声明一个为初始化的字节.
DB 10 ; 声明一个没有label的字节,其值为10.
X DW ? ; 声明一个双字节,未初始化.
Y DD 30000; 声明一个4字节,其值为30000.
还可以声明连续的数据和数组,声明数组时使用DUP关键字
Z DD 1, 2, 3 ; Declare three 4-byte values, initialized to 1, 2, and 3. The value of location Z + 8 will be 3.
bytes DB 10 DUP(?) ; Declare 10 uninitialized bytes starting at location bytes.
arr DD 100 DUP(0); Declare 100 4-byte words starting at location arr, all initialized to 0
str DB 'hello',0 ; Declare 6 bytes starting at the address str, initialized to the ASCII character values for hello and the null (0) byte.
寻址模式
现代X86处理器具有232字节的寻址空间。在上面的例子中,我们用标签(label)表示内存区域,这些标签在实际汇编时,均被32位的实际地址代替。除了支持这种直接的内存区域描述,X86还提供了一种灵活的内存寻址方式,即利用最多两个32位的寄存器和一个32位的有符号常数相加计算一个内存地址,其中一个寄存器可以左移1、2或3位以表述更大的空间。下面例子是汇编程序中常见的方式
mov eax, [ebx] ; 将ebx值指示的内存地址中的4个字节传送到eax中
mov [var], ebx ; 将ebx的内容传送到var的值指示的内存地址中.
mov eax, [esi-4] ; 将esi-4值指示的内存地址中的4个字节传送到eax中
mov [esi+eax], cl ; 将cl的值传送到esi+eax的值指示的内存地址中
mov edx, [esi+4*ebx]; 将esi+4*ebx值指示的内存中的4个字节传送到edx
下面是违反规则的例子:
mov eax, [ebx-ecx] ; 只能用加法
mov [eax+esi+edi], ebx ; 最多只能有两个寄存器参与运算
长度规定
在声明内存大小时,在汇编语言中,一般用DB,DW,DD均可声明的内存空间大小,这种现实声明能够很好地指导汇编器分配内存空间,但是,对于
mov [ebx], 2
如果没有特殊的标识,则不确定常数2是单字节、双字节,还是双字。对于这种情况,X86提供了三个指示规则标记,分别为BYTE PTR, WORD PTR, and DWORD PTR,如上面例子写成:mov BYTE PTR [ebx], 2, mov WORD PTR [ebx], 2, mov DWORD PTR [ebx], 2,则意思非常清晰。
汇编指令
数据传输指令
它们在存贮器和寄存器、寄存器和输入输出端口之间传送数据
1.输入输出端口传送指令.
IN I/O端口输入( 语法: IN 累加器, {端口号│DX} )
OUT I/O端口输出(语法: OUT {端口号│DX},累加器 )
输入输出端口由立即方式指定时, 其范围是 0-255; 由寄存器 DX 指定时, 其范围是 0-65535.
2.通用数据传送指令
MOV 传送字或字节
MOVSX 先符号扩展,再传送
MOVZX 先零扩展,再传送
PUSH 把字压入堆栈
POP 把字弹出堆栈
PUSHA 把AX,CX,DX,BX,SP,BP,SI,DI依次压入堆栈
POPA 把DI,SI,BP,SP,BX,DX,CX,AX依次弹出堆栈
PUSHAD 把EAX,ECX,EDX,EBX,ESP,EBP,ESI,EDI依次压入堆栈
POPAD 把EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX依次弹出堆栈
BSWAP 交换32位寄存器里字节的顺序
XCHG 交换字或字节( 至少有一个操作数为寄存器,段寄存器不可作为操作数)
CMPXCHG比较并交换操作数( 第二个操作数必须为累加器AL/AX/EAX )
XADD 先交换再累加( 结果在第一个操作数里 )
XLAT 字节查表转换
── BX 指向一张 256 字节的表的起点, AL 为表的索引值 (0-255,即0-FFH); 返回 AL 为查表结果. ( [BX+AL]->AL )
3.目的地址传送指令
LEA 装入有效地址. 例: LEA DX,string ;把偏移地址存到DX.
LDS 传送目标指针,把指针内容装入DS 例: LDS SI,string ;把段地址:偏移地址存到DS:SI
LES 传送目标指针,把指针内容装入ES 例: LES DI,string ;把段地址:偏移地址存到ES:DI
LFS 传送目标指针,把指针内容装入FS 例: LFS DI,string ;把段地址:偏移地址存到FS:DI
LGS 传送目标指针,把指针内容装入GS 例: LGS DI,string ;把段地址:偏移地址存到GS:DI
LSS 传送目标指针,把指针内容装入SS 例: LSS DI,string ;把段地址:偏移地址存到SS:DI
4.标志传送指令
LAHF 标志寄存器传送,把标志装入AH
SAHF 标志寄存器传送,把AH内容装入标志寄存器
PUSHF 标志入栈
POPF 标志出栈
PUSHD 32位标志入栈
POPD 32位标志出栈.
算数运算指令
ADD 加法
ADC 带进位加法
INC 加 1
AAA 加法的ASCII码调整
DAA 加法的十进制调整.
SUB 减法
SBB 带借位减法
DEC 减 1
NEC 求反(以 0 减之)
CMP 比较(两操作数作减法,仅修改标志位,不回送结果).
AAS 减法的ASCII码调整
DAS 减法的十进制调整.
MUL 无符号乘法
IMUL 整数乘法
以上两条,结果回送AH和AL(字节运算),或DX和AX(字运算),
AAM 乘法的ASCII码调整
DIV 无符号除法
IDIV 整数除法
以上两条,结果回送:商回送AL,余数回送AH, (字节运算);或商回送AX,余数回送DX, (字运算).
AAD 除法的ASCII码调整.
CBW 字节转换为字(把AL中字节的符号扩展到AH中去)
CWD 字转换为双字(把AX中的字的符号扩展到DX中去)
CWDE 字转换为双字(把AX中的字符号扩展到EAX中去)
CDQ 双字扩展(把EAX中的字的符号扩展到EDX中去)
逻辑运算指令
AND 与运算
OR 或运算
XOR 异或运算
NOT 取反
TEST 测试(两操作数作与运算,仅修改标志位,不回送结果).
SHL 逻辑左移
SHR 逻辑右移
SAL 算术左移(=SHL)
SAR 算术右移(=SHR)
ROL 循环左移
ROR 循环右移
RCL 通过进位的循环左移
RCR 通过进位的循环右移
以上八种移位指令,其移位次数可达255次
移位一次时, 可直接用操作码. 如 SHL AX,1
移位>1次时, 则由寄存器CL给出移位次数
如 MOV CL,04
SHL AX,CL
串指令
DS:SI 源串段寄存器:源串变址
ES:DI 目标串段寄存器:目标串变址.
CX 重复次数计数器
AL/AX 扫描值
D标志 0表示重复操作中SI和DI应自动增量; 1表示应自动减量
Z标志 用来控制扫描或比较操作的结束
MOVS 串传送 (MOVSB 传送字符 MOVSW 传送字 MOVSD 传送双字 )
CMPS 串比较 (CMPSB 比较字符 CMPSW 比较字 )
SCAS 串扫描,把AL或AX的内容与目标串作比较,比较结果反映在标志位
LODS 装入串,把源串中的元素(字或字节)逐一装入AL或AX中. (LODSB 传送字符 LODSW 传送字 LODSD 传送双字)
STOS 保存串,是LODS的逆过程
REP 当CX/ECX<>0时重复
REPE/REPZ 当ZF=1或比较结果相等,且CX/ECX<>0时重复
REPNE/REPNZ 当ZF=0或比较结果不相等,且CX/ECX<>0时重复
REPC 当CF=1且CX/ECX<>0时重复
REPNC 当CF=0且CX/ECX<>0时重复
程序转移指令
无条件转移指令 (长转移)
JMP 无条件转移指
CALL 过程调用
RET/RETF过程返回
call, ret— Subroutine call and return
这两条指令实现子程序(过程、函数等意思)的调用及返回。call指令首先将当前执行指令地址入栈,然后无条件转移到由标签指示的指令。与其它简单的跳转指令不同,call指令保存调用之前的地址信息(当call指令结束后,返回到调用之前的地址)。
ret指令实现子程序的返回机制,ret指令弹出栈中保存的指令地址,然后无条件转移到保存的指令地址执行。call,ret是函数调用中最关键的两条指令。
调用规则
为了加强程序员之间的协作及简化程序开发进程,设定一个函数调用规则非常必要,函数调用规则规定函数调用及返回的规则,只要遵照这种规则写的程序均可以正确执行,从而程序员不必关心诸如参数如何传递等问题;另一方面,在汇编语言中可以调用符合这种规则的高级语言所写的函数,从而将汇编语言程序与高级语言程序有机结合在一起。
调用规则分为两个方面,及调用者规则和被调用者规则,如一个函数A调用一个函数B,则A被称为调用者(Caller),B被称为被调用者(Callee)。
下图显示一个调用过程中的内存中的栈布局:
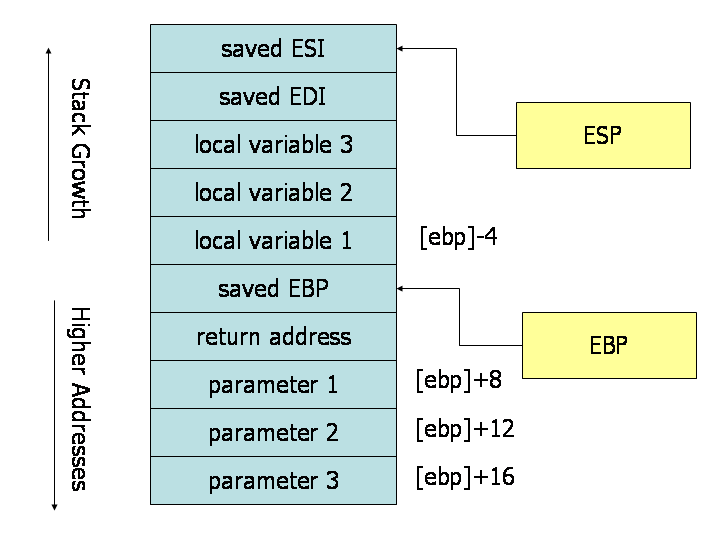
在X86中,栈增长方向与内存编号增长方向相反。
Caller Rules
调用者规则包括一系列操作,描述如下:
1.在调用子程序之前,调用者应该保存一系列被设计为调用者保存的寄存器的值。调用者保存寄存器有eax,ecx,edx。由于被调用的子程序会修改这些寄存器,所以为了在调用子程序完成之后能正确执行,调用者必须在调用子程序之前将这些寄存器的值入栈。
2.在调用子程序之前,将参数入栈。参数入栈的顺序应该是从最后一个参数开始,如上图中parameter3先入栈。
3.利用call指令调用子程序。这条指令将返回地址放置在参数的上面,并进入子程序的指令执行。(子程序的执行将按照被调用者的规则执行)
当子程序返回时,调用者期望找到子程序保存在eax中的返回地址。为了恢复调用子程序执行之前的状态,调用者应该执行以下操作:
1.清除栈中的参数;
2.将栈中保存的eax值、ecx值以及edx值出栈,恢复eax、ecx、edx的值(当然,如果其它寄存器在调用之前需要保存,也需要完成类似入栈和出栈操作)
Example
如下代码展示了一个调用子程序的调用者应该执行的操作。此汇编程序调用一个具有三个参数的函数_myFunc,其中第一个参数为eax,第二个参数为常数216,第三个参数为var指示的内存中的值。
push [var] ; Push last parameter first
push 216 ; Push the second parameter
push eax ; Push first parameter last
call _myFunc ; Call the function (assume C naming)
add esp, 12
在调用返回时,调用者必须清除栈中的相应内容,在上例中,参数占有12个字节,为了消除这些参数,只需将ESP加12即可。
_myFunc的值保存在eax中,ecx和edx中的值也许已经被改变,调用者还必须在调用之前保存在栈中,并在调用结束之后,出栈恢复ecx和edx的值。
被调用者应该遵循如下规则:
1.将ebp入栈,并将esp中的值拷贝到ebp中,其汇编代码如下:
push ebp
mov ebp, esp
上述代码的目的是保存调用子程序之前的基址指针,基址指针用于寻找栈上的参数和局部变量。当一个子程序开始执行时,基址指针保存栈指针指示子程序的执行。为了在子程序完成之后调用者能正确定位调用者的参数和局部变量,ebp的值需要返回。
2.在栈上为局部变量分配空间。
3.保存callee-saved寄存器的值,callee-saved寄存器包括ebx,edi和esi,将ebx,edi和esi压栈。
4.在上述三个步骤完成之后,子程序开始执行,当子程序返回时,必须完成如下工作:
(1)将返回的执行结果保存在eax中
(2)弹出栈中保存的callee-saved寄存器值,恢复callee-saved寄存器的值(ESI和EDI)
(3)收回局部变量的内存空间。实际处理时,通过改变EBP的值即可:mov esp, ebp。
(4)通过弹出栈中保存的ebp值恢复调用者的基址寄存器值。
(5)执行ret指令返回到调用者程序。
Example
.486
.MODEL FLAT
.CODE
PUBLIC _myFunc
_myFunc PROC
; Subroutine Prologue
push ebp ; Save the old base pointer value.
mov ebp, esp ; Set the new base pointer value.
sub esp, 4 ; Make room for one 4-byte local variable.
push edi ; Save the values of registers that the function
push esi ; will modify. This function uses EDI and ESI.
; (no need to save EBX, EBP, or ESP)
; Subroutine Body
mov eax, [ebp+8] ; Move value of parameter 1 into EAX
mov esi, [ebp+12] ; Move value of parameter 2 into ESI
mov edi, [ebp+16] ; Move value of parameter 3 into EDI
mov [ebp-4], edi ; Move EDI into the local variable
add [ebp-4], esi ; Add ESI into the local variable
add eax, [ebp-4] ; Add the contents of the local variable
; into EAX (final result)
; Subroutine Epilogue
pop esi ; Recover register values
pop edi
mov esp, ebp ; Deallocate local variables
pop ebp ; Restore the caller's base pointer value
ret
_myFunc ENDP
END
子程序首先通过入栈的手段保存ebp,分配局部变量,保存寄存器的值。
在子程序体中,参数和局部变量均是通过ebp进行计算。由于参数传递在子程序被调用之前,所以参数总是在ebp指示的地址的下方(在栈中),因此,上例中的第一个参数的地址是ebp+8,第二个参数的地址是ebp+12,第三个参数的地址是ebp+16;而局部变量在ebp指示的地址的上方,所有第一个局部变量的地址是ebp-4,而第二个这是ebp-8.
条件转移指令
(短转移,-128到+127的距离内) ( 当且仅当(SF XOR OF)=1时,OP1<OP2 )
JA/JNBE 不小于或不等于时转移
JAE/JNB 大于或等于转移
JB/JNAE 小于转移
JBE/JNA 小于或等于转移
以上四条,测试无符号整数运算的结果(标志C和Z)
JG/JNLE 大于转移
JGE/JNL 大于或等于转移
JL/JNGE 小于转移
JLE/JNG 小于或等于转移
以上四条,测试带符号整数运算的结果(标志S,O和Z)
JE/JZ 等于转移
JNE/JNZ 不等于时转移
JC 有进位时转移
JNC 无进位时转移
JNO 不溢出时转移
JO 溢出转移
JNP/JPO 奇偶性为奇数时转移
JP/JPE 奇偶性为偶数时转移
JNS 符号位为 “0” 时转移
JS 符号位为 "1" 时转移
循环控制指令(短转移)
LOOP CX不为零时循环
LOOPE/LOOPZ CX不为零且标志Z=1时循环
LOOPNE/LOOPNZ CX不为零且标志Z=0时循环
JCXZ CX为零时转移
JECXZ ECX为零时转移
中断指令
INT 中断指令
NTO 溢出中断
IRET 中断返回
处理器控制指令
HLT 处理器暂停, 直到出现中断或复位信号才继续
WAIT 当芯片引线TEST为高电平时使CPU进入等待状态
ESC 转换到外处理器
LOCK 封锁总线
NOP 空操作
STC 置进位标志位
STD 置方向标志位
STI 置中断允许位
CMC 进位标志取反
CLC 清进位标志位
CLD 清方向标志位
CLI 清中断允许位
伪指令
DB 定义字节
DW 定义字(2字节)
PROC 定义过程
ENDP 过程结束
SEGMENT 定义段
ASSUME 建立段寄存器寻址
ENDS 段结束
END 程序结束
汇编语法格式
1.在 AT&T 汇编格式中,寄存器名要加上 ‘%’ 作为前缀;而在 Intel 汇编格式中,寄存器名不需要加前缀。例如:
AT&T 格式 Intel 格式
pushl %eax push eax
2.在 AT&T 汇编格式中,用 ‘$’ 前缀表示一个立即操作数;而在 Intel 汇编格式中,立即数的表示不用带任何前缀。例如:
AT&T 格式 Intel 格式
pushl $1 push 1
3.AT&T 和 Intel 格式中的源操作数和目标操作数的位置正好相反。在 Intel 汇编格式中,目标操作数在源操作数的左边;而在 AT&T 汇编格式中,目标操作数在源操作数的右边。例如:
AT&T 格式 Intel 格式
addl $1, %eax add eax, 1
4.在 AT&T 汇编格式中,操作数的字长由操作符的最后一个字母决定,后缀’b’、’w’、’l’分别表示操作数为字节(byte,8 比特)、字(word,16 比特)和长字(long,32比特);而在 Intel 汇编格式中,操作数的字长是用 “byte ptr” 和 “word ptr” 等前缀来表示的。例如:
AT&T 格式 Intel 格式
movb val, %al mov al, byte ptr val
5.在 AT&T 汇编格式中,绝对转移和调用指令(jump/call)的操作数前要加上’*’作为前缀,而在 Intel 格式中则不需要。
6.远程转移指令和远程子调用指令的操作码,在 AT&T 汇编格式中为 “ljump” 和 “lcall”,而在 Intel 汇编格式中则为 “jmp far” 和 “call far”,即:
AT&T 格式 Intel 格式
ljump $section, $offset jmp far section:offset
lcall $section, $offset call far section:offset
与之相应的远程返回指令则为:
AT&T 格式 Intel 格式
lret $stack_adjust ret far stack_adjust
7.在 AT&T 汇编格式中,内存操作数的寻址方式是
section:disp(base, index, scale)
而在 Intel 汇编格式中,内存操作数的寻址方式为:
section:[base + index*scale + disp]
由于 Linux 工作在保护模式下,用的是 32 位线性地址,所以在计算地址时不用考虑段基址和偏移量,而是采用如下的地址计算方法:
disp + base + index * scale
下面是一些内存操作数的例子:
AT&T 格式 Intel 格式
movl -4(%ebp), %eax mov eax, [ebp - 4]
movl array(, %eax, 4), %eax mov eax, [eax*4 + array]
movw array(%ebx, %eax, 4), %cx mov cx, [ebx + 4*eax + array]
movb $4, %fs:(%eax) mov fs:eax, 4
64位和32位的寄存器和汇编的比较
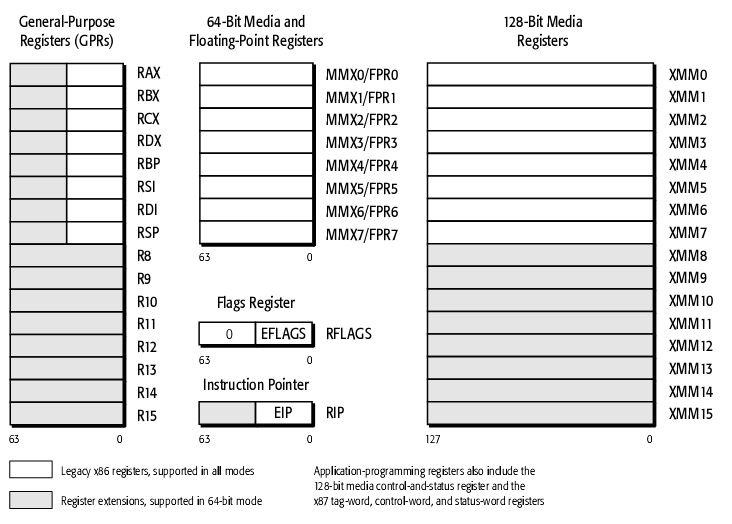
X64多了8个通用寄存器:R8、R9、R10、R11、R12、R13、R14、R15,当然,它们都是64位的。另外还增加了8个128位XMM寄存器,不过通常用不着。
X32中原有的寄存器在X64中均为扩展为64位,且名称的第一个字母从E改为R。不过我们还是可以在64位程序中调用32位的寄存器,如RAX(64位)、EAX(低32)、AX(低16位)、AL(低8位)、AH(8到15位),相应的有R8、R8D、R8W和R8B。不过不要在程序中使用如AH之类的寄存器,因为在AMD的CPU上这种用法会与某些指令产生冲突
64位寄存器分配的不同:

64位有16个寄存器,32位只有8个。但是32位前8个都有不同的命名,分别是e ,而64位前8个使用了r代替e,也就是r 。e开头的寄存器命名依然可以直接运用于相应寄存器的低32位。而剩下的寄存器名则是从r8 - r15,其低位分别用d,w,b指定长度。
32位使用栈帧来作为传递的参数的保存位置,而64位使用寄存器,分别用rdi,rsi,rdx,rcx,r8,r9作为第1-6个参数。rax作为返回值
64位没有栈帧的指针,32位用ebp作为栈帧指针,64位取消了这个设定,rbp作为通用寄存器使用
64位支持一些形式的以PC相关的寻址,而32位只有在jmp的时候才会用到这种寻址方式。

mov指令和push pop扩展了movq系列的mov和pushq以及popq用来操作quad word。
注:movabsq不是32位的扩展,是纯新增的指令。用来将一个64位的字面值直接存到一个64位寄存器中。因为movq只能将32位的值存入,所以新增了这样一条指令。

过程(函数)调用的不同
参数通过寄存器传递(见前文)
callq 在栈里存放一个8位的返回地址
许多函数不再有栈帧,只有无法将所有本地变量放在寄存器里的才会在栈上分配空间。
函数可以获取到栈至多128字节的空间。这样函数就可以在不更改栈指针的情况下在栈上存储信息(也就是说,可以提前用rsp以下的128字节空间,这段空间被称为red zone,在x86-64里,时刻可用)
不再有栈帧指针。现在栈的位置和栈指针相关。大多数函数在调用的一开始就分配全部所需栈空间,之后保持栈指针不改变。
一些寄存器被设计成为被调用者-存储的寄存器。这些必须在需要改变他们值的时候存储他们并且之后恢复他们。
参数传递的不同
6个寄存器用来传递参数
剩下的寄存器按照之前的方式传递(不过是与rsp相关了,ebp不再作为栈帧指针,并且从rsp开始第7个参数,rsp+8开始第8个,以此类推)
调用时,rsp向下移动8位(存入返回地址),寄存器参数无影响,第7个及之后的参数现在则是从rsp+8开始第7个,rsp+16开始第8个,以此类推
栈帧的不同
很多情况下不再需要栈帧,比如在没有调用别的函数,且寄存器足以存储参数,那么就只需要存储返回地址即可。 需要栈帧的情况:
本地变量太多,寄存器不够
一些本地变量是数组或结构体
函数使用了取地址操作符来计算一个本地变量的地址
函数必须用栈传送一些参数给另外一个函数
函数需要保存一些由被调用者存储的寄存器的状态(以便于恢复)
但是现在的栈帧经常是固定大小的,在函数调用的最开始就被设定,在整个调用期间,栈顶指针保持不变,这样就可以通过对其再加上偏移量来对相应的值进行操作,于是EBP就不再需要作为栈帧指针了。
虽然很多时候我们认为没有“栈帧”,但是每次函数调用都一定有一个返回地址被压栈,我们可以也认为这一个地址就是一个“栈帧”,因为它也保存了调用者的状态。
基本汇编程序
1.Hello, world!
32位
section .data
msg db "Hello, world!", 0xA
len equ $ - msg
section .text
global main
main:
mov edx, len
mov ecx, msg
mov ebx, 1
mov eax, 4
int 0x80
mov ebx, 0
mov eax, 1
int 0x80
righteous@ubuntu:~/Desktop/asm$ nasm -f elf32 hello.asm
righteous@ubuntu:~/Desktop/asm$ gcc -m32 -o hello hello.o
righteous@ubuntu:~/Desktop/asm$ ./hello
Hello, world!
64位
extern printf
section .data
msg: db "Hello world", 0
fmt: db "%s", 10, 0
section .text
global main
main:
push rbp
mov rdi,fmt
mov rsi,msg
mov rax,0
call printf
pop rbp
mov rax,0
ret
righteous@ubuntu:~/Desktop/asm$ nasm -f elf64 hello_x64.asm
righteous@ubuntu:~/Desktop/asm$ gcc -m64 -o hello_x64 hello_x64.o
righteous@ubuntu:~/Desktop/asm$ ./hello_x64
Hello world
2.求和
extern printf
section .data
a: dd 5
b: dd 7
fmt: db "sum:c=a+b=%d", 10, 0
section .bss
c: resd 1
section .text
global main
main:
push ebp
mov ebp,esp
mov eax, [a]
add eax, [b]
mov [c], eax
push eax
push dword [c]
push dword fmt
call printf
add esp, 12
mov esp, ebp
pop ebp
mov eax,0
ret
righteous@ubuntu:~/Desktop/asm$ nasm -f elf32 sum.asm
righteous@ubuntu:~/Desktop/asm$ gcc -m32 -o sum sum.o
righteous@ubuntu:~/Desktop/asm$ ./sum
sum:c=a+b=12
3.斐波那契数列
extern printf
section .data
format: db "SDPC==>%ld", 10, 0
section .text
global main
main:
push rbx
mov ecx, 10
xor rax, rax
xor rbx, rbx
inc rbx
Fibonacci:
push rax
push rcx
mov rdi, format
mov rsi, rax
xor rax, rax
call printf
pop rcx
pop rax
mov rdx, rax
mov rax, rbx
add rbx, rdx
dec ecx
jnz Fibonacci
pop rbx
ret
righteous@ubuntu:~/Desktop/asm$ gcc -m64 -o fibonacci fibonacci.o
righteous@ubuntu:~/Desktop/asm$ nasm -f elf64 fibonacci.asm
righteous@ubuntu:~/Desktop/asm$ gcc -m64 -o fibonacci fibonacci.o
righteous@ubuntu:~/Desktop/asm$ ./fibonacci
SDPC==>0
SDPC==>1
SDPC==>1
SDPC==>2
SDPC==>3
SDPC==>5
SDPC==>8
SDPC==>13
SDPC==>21
SDPC==>34